What Is Fine-Tuning in the Context of LLMs and How Does It Work?
- Artificial Intelligence
- What Is Fine-Tuning in the Context of LLMs and How Does It Work?



Why you can trust our content
The tech space is full of hype and difficult terms; we take the reliability standards to new heights. Our blog content is backed by:
Learn more
- Experienced tech professionals, developers, and product engineers
- First-hand data from real projects and in-house case studies
- Verified standards from trusted sources like Statista and BD
Let’s Work Together
You’ve probably interacted with an LLM—whether through ChatGPT, Google Bard, or a chatbot on your favorite site. But what if the answers felt… off? That’s where fine-tuning steps in.
Fine-tuning allows businesses and developers to reshape general-purpose models like GPT-4 into sharp, industry-specific tools. It bridges the gap between “pretty good” and “exactly what I need.” In this blog, you’ll learn what fine-tuning means, how it differs from prompt engineering, how to prepare training data, and why it matters in real-world applications.
Let’s EXPLORE one of the most misunderstood yet powerful tools in AI today.
What Is Fine-Tuning in AI?
In AI, fine-tuning is the process of training a pre-trained model further on a smaller, domain-specific dataset. Instead of starting from scratch, it refines an existing model’s knowledge to perform better on targeted tasks.
Think of it as teaching a fluent English speaker how to write legal contracts—they already know the language, but now you’re giving them the jargon, tone, and rules of the courtroom.
Fine-tuning boosts:
- Accuracy in specific use cases
- Relevance of outputs
- Brand or industry alignment
The Role of Fine-Tuning in Large Language Models (LLMs)
LLMs like GPT‑4 or LLaMA are trained on massive datasets, but they lack context for niche domains out of the box. Fine-tuning helps them:
- Understand company-specific vocabulary
- Align tone and language to brand
- Follow custom formatting or guidelines
For example, a legal tech firm may fine-tune an LLM to write NDAs, while a marketing agency might optimize it for catchy ad copy.
According to OpenAI (2024), fine-tuned models are up to 30% more accurate in specific tasks compared to base models with prompt engineering alone.
How Does Fine-Tuning Work in the Context of LLMs?
Step-by-step Breakdown:
- Start with a base model (e.g., GPT-3.5, LLaMA 2)
- Prepare a labeled dataset (prompt → ideal response)
- Train the model further using a smaller learning rate
- Validate performance through benchmarks and edge-case testing
- Deploy and monitor outputs for quality control
Technical Notes:
- Fine-tuning often requires a GPU/TPU environment.
- Formats like JSONL are common for feeding in training data.
- Training can take hours to days depending on data volume.
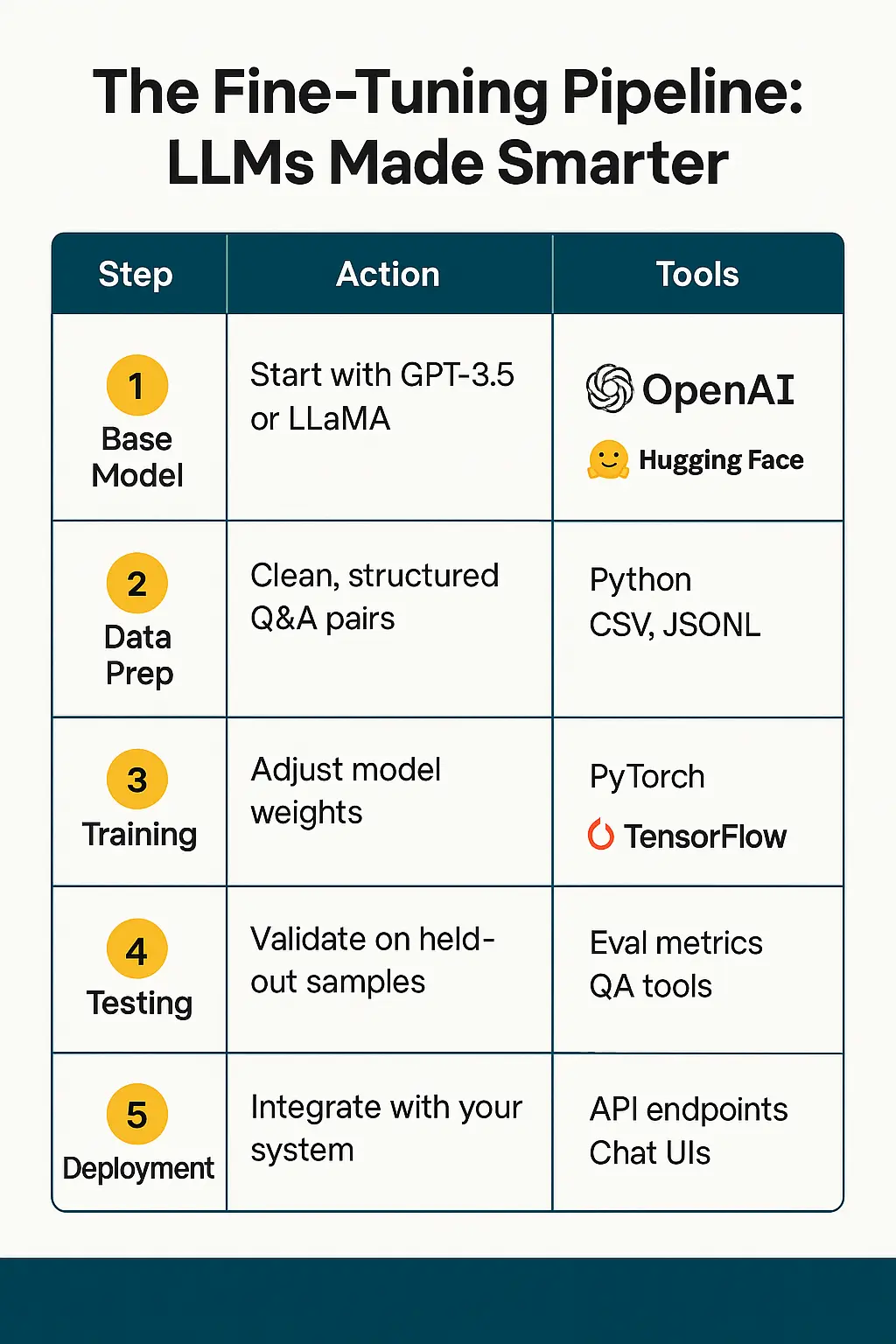
| Step | Action | Tools |
|---|---|---|
|
1. Base Model
|
Start with GPT-3.5 or LLaMA |
OpenAI, HuggingFace
|
|
2. Data Prep
|
Clean, structured Q&A pairs
|
Python, CSV, JSONL
|
|
3. Training |
Adjust model weights
|
PyTorch, TensorFlow
|
|
4. Testing
|
Validate on held-out samples
|
Eval metrics, QA tools
|
|
5. Deployment
|
Integrate with your system
|
API endpoints, Chat UIs
|
How Fine-Tuning Differs from Prompt Engineering
Here’s the major difference:
| Feature | Fine-Tuning | Prompt Engineering |
|---|---|---|
|
Access Required
|
Model-level training access
|
Public API or UI
|
|
Data Volume
|
Requires 100s–1,000s of samples
|
Single prompt |
|
Customization
|
Deep & permanent
|
Temporary & surface-level
|
|
Cost
|
Higher (training)
|
Lower (API cost only)
|
|
Use Case
|
Brand tone, complex outputs
|
One-time tasks, general answers
|
When to use each?
- Use prompt engineering if your changes are minor or temporary.
- Use fine-tuning when consistency, depth, and brand specificity matter.
Real Use Case:
A UK automotive brand fine-tuned a GPT model to describe wrap designs with precision—color codes, surface texture, finish type—something no prompt could reliably reproduce at scale.
This is the most overlooked yet crucial step.
How to Prepare Your Dataset:
- Pair prompts with ideal responses: no typos, consistent tone
- Format in JSONL: each line: { “prompt”: “…”, “completion”: “…” }
- Avoid noisy data: inconsistent examples confuse the model
- Use real scenarios: customer queries, internal knowledge, FAQs
- Validate internally: have subject-matter experts review samples
Pro Tip: Include edge cases and tone variations—real usage isn’t perfect, so neither should the data be.
Tools to Help:
- Label Studio
- Doccano
- Pandas (for cleaning in Python)

Challenges in Fine-Tuning LLMs
Common Pitfalls:
- Overfitting: Model memorizes responses, lacks flexibility
- Insufficient data: Under-trained, outputs inconsistent
- Hallucinations: If data is poorly structured
- Cost spikes: Training compute can get expensive
- Maintenance: Needs re-fine-tuning as trends/language evolve
Overcoming Them:
- Use dropout regularization
- Feed diverse examples (not all identical)
- Always monitor real-world performance
- Store versioned training datasets
Pro Tip: Start small. Fine-tune on 200–500 samples, test quality, and then scale up.
Benefits of Fine-Tuning LLMs
Results You Can Expect:
- Higher accuracy on specific tasks
- Better alignment with brand voice
- Faster content generation with minimal edits
- Improved customer experience through personalization
- Competitive edge with tailored AI assistants
A recent HubSpot survey (2025) revealed 78% of businesses using fine-tuned models reported a noticeable uplift in quality compared to generic models.
Practical Tips: Making Fine-Tuning Work for You
Here’s your 5‑point action checklist:
- Define your goal (e.g. writing vehicle wrap content)
- Prepare real sample data from your business
- Clean and structure that data carefully
- Choose the right base model (e.g., GPT‑3.5, LLaMA 2)
- Test, review, deploy—and repeat as needed
Conclusion
Fine-tuning gives you more than just better results—it gives you control. You’re no longer stuck with generic answers. You get a consistent tone, deeper relevance, and an AI that feels like part of your team.
Whether you’re in automotive, education, e-commerce, or finance, LLM fine-tuning makes the difference between generic automation and brand-specific intelligence.
So the next time someone asks, “How do I get better output from AI?” You’ll know the real answer: fine-tune it.
Need Precision from Your AI Content?
Share this post on social media:
Zain Ali is a dynamic AI engineer and software development expert known for crafting intelligent, scalable, and future-ready digital solutions. With extensive experience in artificial intelligence, machine learning, and web development, he empowers businesses by building systems that drive performance, automation, and innovation.
